17 Project-based workflow
As our skills as data analysts grow, we begin to understand that our ability to realise our full potential goes beyond the data tools that we have chosen to use or have been made to use. The importance of surrounding systems and infrastructure for ensuring reproducibility and long-term preservation of our work becomes increasingly significant. However, a lack of formal training or mentorship in managing these systems often leads to either feeling overwhelmed by technology or resorting to self-exploration without proper guidance.
This chapter aims to guide you gracefully into the exploration of this realm of efficient, effective, and reproducible data workflows. The concepts and practices discussed here may highlight current and existing practices that you have that are ineffectual, disorganised, and irreproducible. If so, we encourage you not to worry about these past mistakes but instead use them to raise the bar for your new work. Small but meaningful incremental changes add up over time, transforming your data quality of life.
In this chapter, we will discuss concepts and practices borrowed from the computational sciences field that use programming languages to record and automate their processes and translate them for use with the spreadsheet software that is sort of a hybrid with data processes implemented through both point-and-click steps via the mouse and through in cell commands or functions for performing calculations and operations. This translation as applied to spreadsheets is not high fidelity given the shortcomings and limitations of spreadsheets (as discussed in Section 16.3.2) but still provides enough structure and rigour compared to the typical and common ad hoc and unstructured use of spreadsheets.
17.1 Data processes as livestock rather than pets
In modern data and computing, a common analogy used to describe the management of data and computational processes is that of managing a herd of livestock compared to taking care of an individual household pet. For example, in cloud computing, individual servers are treated like “livestock” in that they can be easily destroyed and replaced via automation.


It is recommended that we adopt a similar mindset when managing our data and data processes - design and develop appropriate data systems that manage data and data processes as disposable and rebuilt and re-implemented as needed rather than as precious “pets”. We recommend this approach because if your workflow relies on an individual session or workspace in a non-reproducible way, it creates unnecessary risk and complexity. Instead, the focus should be on saving and relying on code and documentation to ensure reproducibility.
Applying this approach with spreadsheets is not as straightforward given the peculiarities of the tool compared to programming languages that use code to record each step of the workflow. However, steps can be done that can facilitate as much reproducibility when using spreadsheets.
17.1.1 Detailed documentation for point-and-click mouse-based steps
Point-and-click steps in a workflow implemented using a mouse can be documented either in a specific worksheet within the spreadsheet that is just meant for documentation. The documentation can also be done on a separate document either in Word document (.docx) format or in a text-based format such as Markdown (.md) or text file (.txt) written using a text editor (see Tip 17.1 for recommendations on text editors for different operating software). This separate file should be included within the directory where the spreadsheet file is located (see Figure 17.3). An example of a text file documenting steps for data cleaning is shown in Figure 17.4.
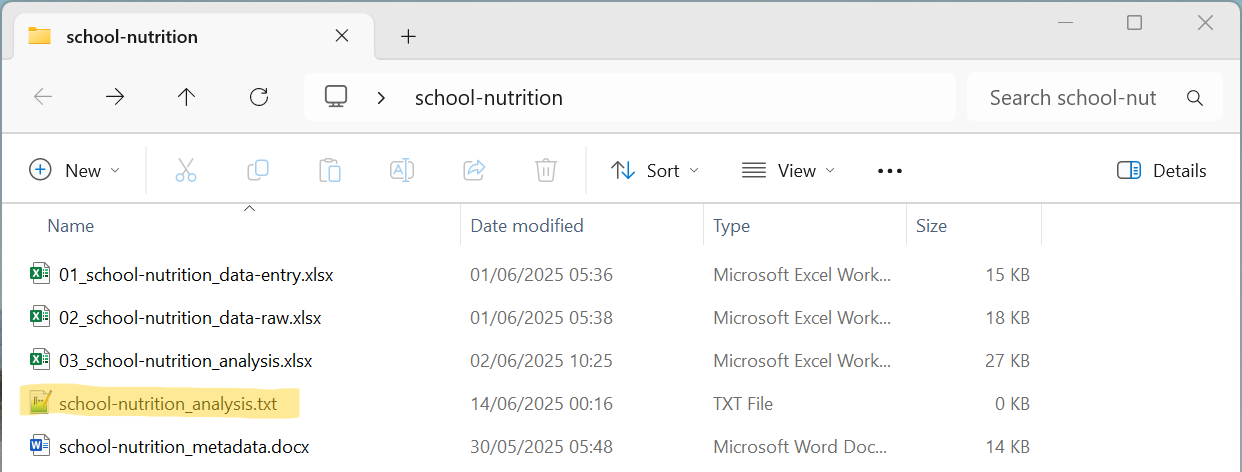
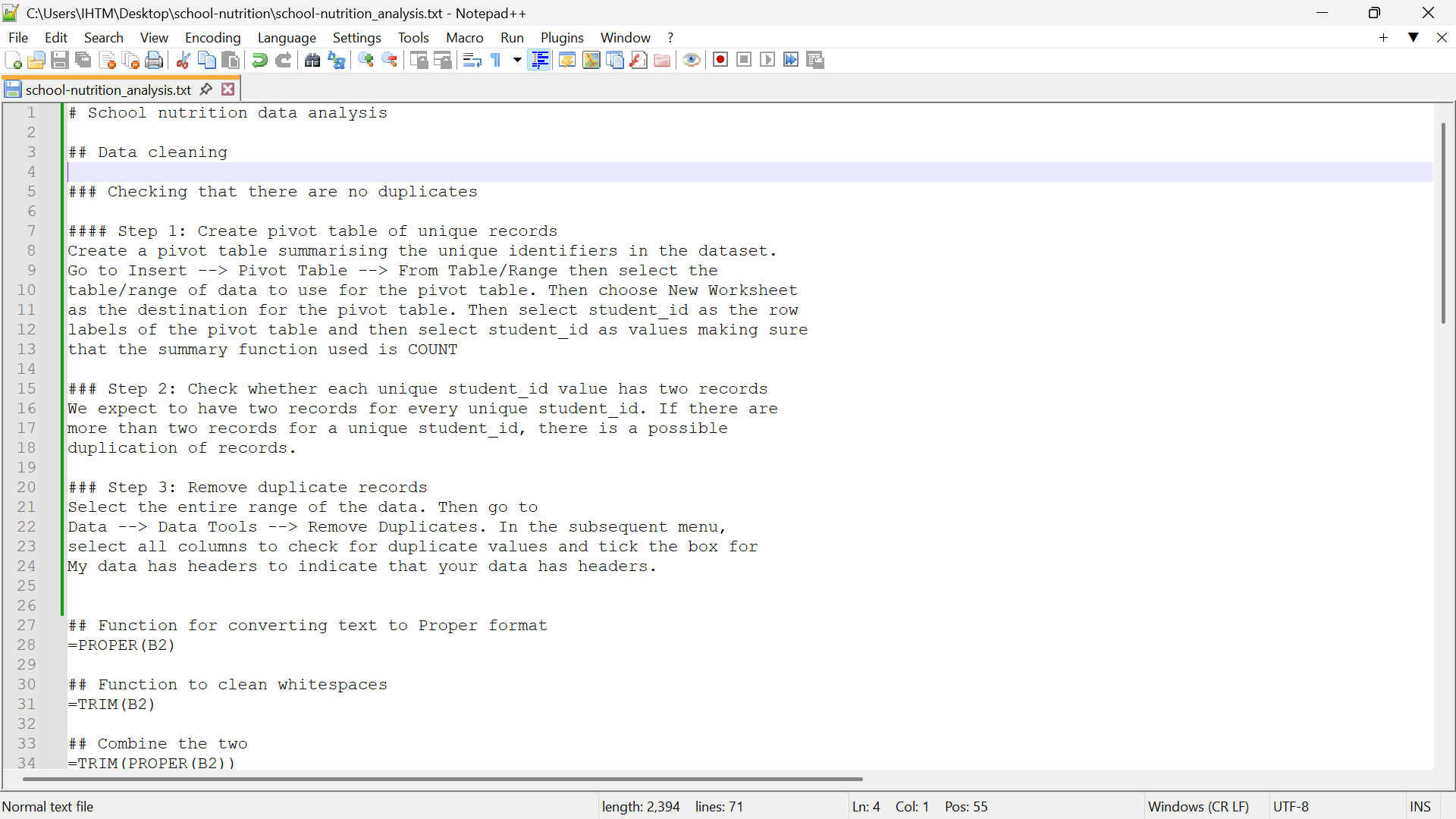
17.1.2 Saving a source for written functions in spreadsheets
Saving a text-based source file for the syntax of in cell functions and calculations used in a spreadsheet is one way of recording the non-mouse steps of the spreadsheet workflow. A text editor (rather than a word processor) would be ideal for this as the syntax of the function or formula will be shown more appropriately. If you are already using a text editor for documenting mouse-based steps of the spreadsheet workflow, it would be ideal to use the same text file to record in cell functions and calculations as shown in Figure 17.4.
Following are recommended text editors for use with different operating software:
For Windows
Notepad++ is a free source code editor and Notepad replacement that supports several languages. Running in the Microsoft Windows environment, its use is governed by GNU General Public License.
For Mac
CodeEdit is an exciting new code editor written entirely and unapologetically for macOS. Develop any project using any language at speeds like never before with increased efficiency and reliability in an editor that feels right at home on your Mac.
Create a text file to associate with every spreadsheet project that you are working on. Save the text file within the same directory as the associated spreadsheet as shown in Figure 17.3.
17.2 Organise work into projects
Organising work into projects is another best practice that provides organisational clarity for our data and data processes. Whilst this can be interpreted in many ways and that some of you may argue that you already organise your work with data in projects, the following key points give a clear indication/definition of what we mean by project-based workflows.
17.2.1 File system discipline
Simply put, this means putting all the files related to a single project in a designated folder. This applies to data, code, figures, notes, including the documentation and source files described earlier (see Figure 17.5). Depending on complexity of your project and on yours or your team’s/organisation’s preferences, you might enforce further organisation into subfolders. Related and relevant file system practices are discussed in Section 17.2.3.
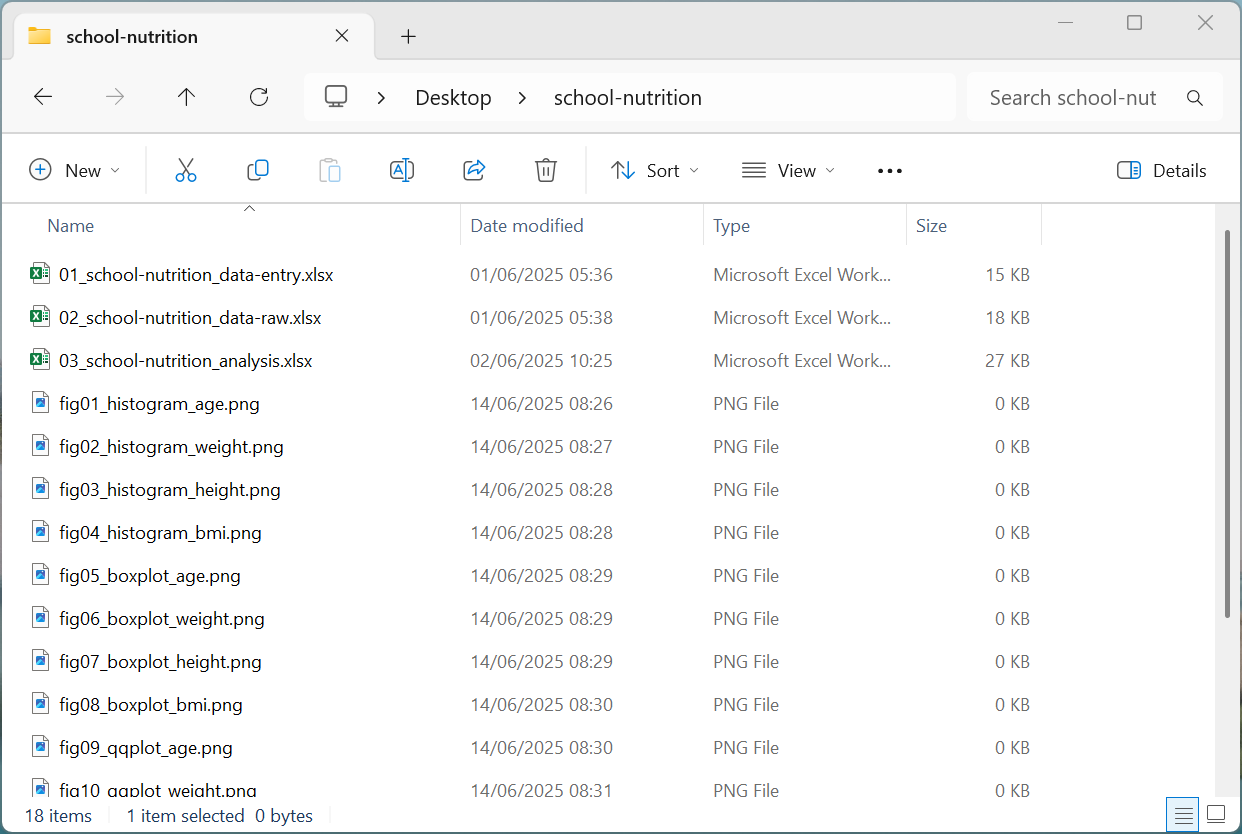
17.2.2 File path discipline
All paths are relative and, by default, relative to the project’s folder. This is particularly important when you are referencing data found in one spreadsheet from within another spreadsheet for data analysis and visualisation. If files are within the same project, then relative paths make it easy to refer to associated or ancillary spreadsheets required for full analysis, visualisation, and reporting.
17.2.3 File naming
File organisation and naming are powerful weapons against chaos.
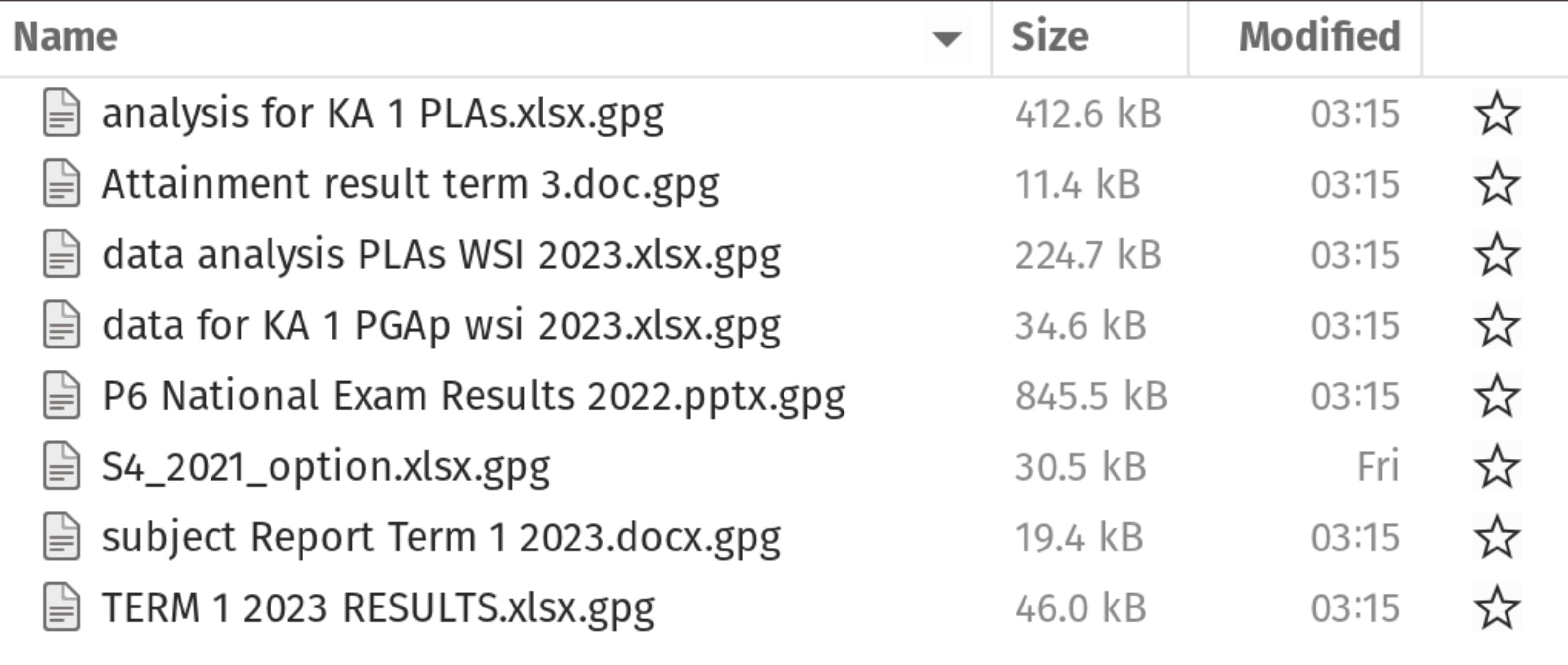
Best practices in file naming are based on the following three principles:
Machine-readable
Machine-readable file names avoid spaces, punctuation, accented characters, and case sensitivity. Avoiding these makes file names easier to index and search via use of regular expressions and wild card matching or globbing.
A regular expression, usually shortened as regex or regexp and sometimes referred to as rational expression, is a sequence of characters that specifies a match pattern in text. Usually such patterns are used by string-searching algorithms for “find” or “find and replace” operations on strings, or for input validation.
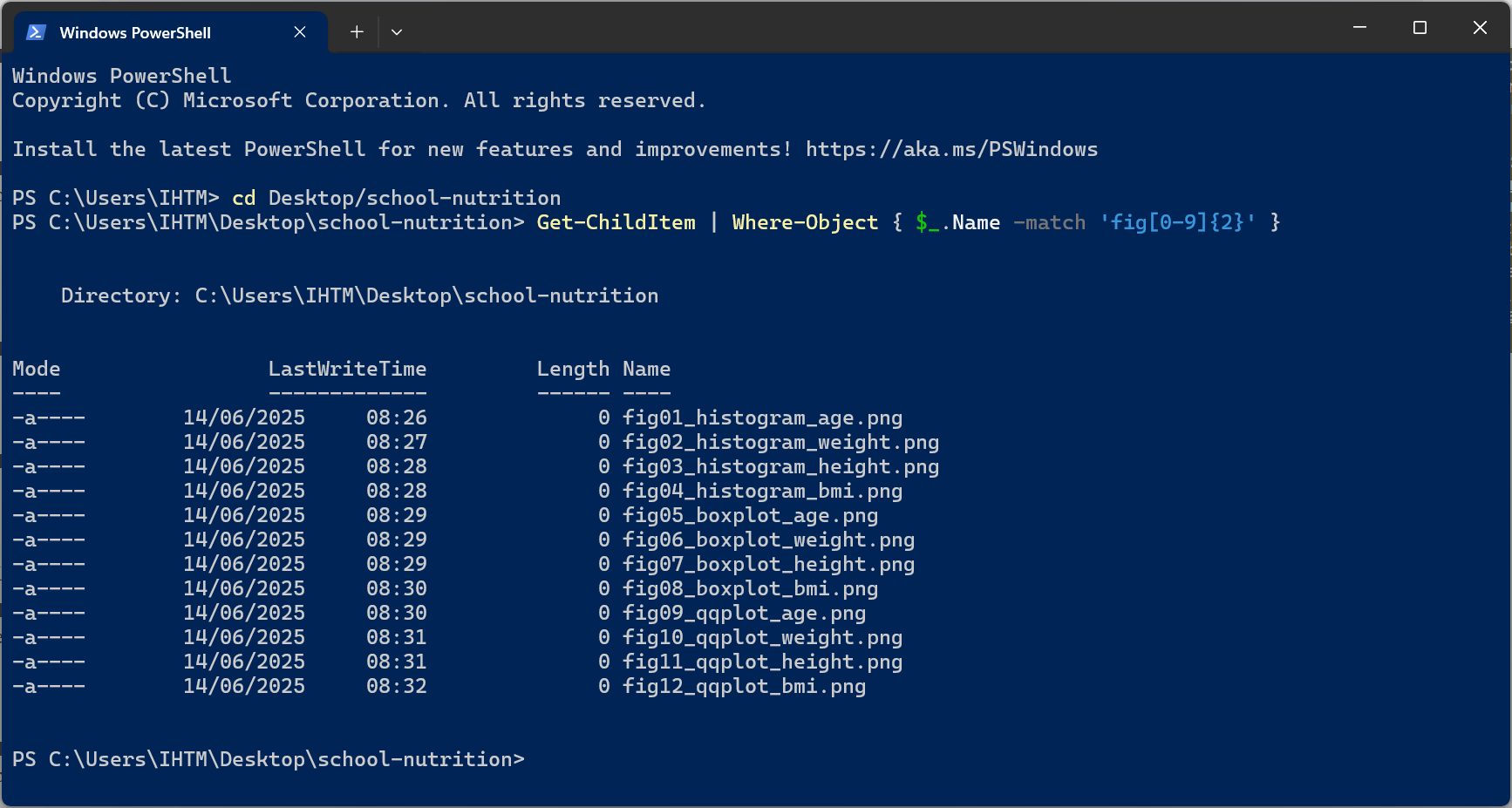
Globbing, also known as wildcard matching, is a technique used in computer systems to match multiple files or paths based on patterns containing wildcards like * (asterisk) and ? (question mark). It’s a common way to specify a set of files or paths in command-line interfaces, file managers, and programming languages. In simpler terms: globbing allows you to use patterns to find files that share a common naming structure, without having to specify each file individually.
Machine-readable file names have deliberate use of delimiters/space-holders such as underscore (_) or hyphen (-). The general rule is that _ is used to delimit units of metadata while - is used to delimit words so that they are more readable. This system allows for much easier recovery of metadata from file names.
Human-readable
A file name is human-readable if it contains information on what the file contains. It should be easy to figure out what something is based on its file name. This is a similar concept to a slug from semantic URLs. A URL slug is the unique, identifiable portion of a web address (URL) that follows the domain name (e.g., “google.com”). It essentially acts as a “name tag” for a specific page or resource on a website, helping both users and search engines understand what the page is about.
Plays well with default ordering
File names should play well with default ordering. This is usually achieved by:
- putting something numeric first in a file name;
using the ISO 8601 standard (YYYY-MM-DD) for dates; and,
pad the left side of other numbers with zeros.
17.3 Gains from project-based workflows
Developing the different project-based workflow habits described above collectively yields the most significant benefits. These practices ensure projects can move seamlessly across different computers or environments while maintaining reliability. Project-based workflow approach is a practical convention for achieving consistent behaviour across users and time comparable to societal norms like agreeing on traffic rules (e.g., driving on the left or right). Adhering to these conventions - whether in computing or in broader civilisation - constrains individual actions slightly for greater functionality and safety.